보통 인터넷이라 하면 웹을 떠올린다.
하지만 인터넷이 웹인 것은 아니다.
컴퓨터 하나에는 여러 개의 서버가 존재하고, 각 서버는 다른 포트번호를 사용한다.
웹은 80번 포트를 이용하고 있고, 이메일은 25번, FTP는 21번을 사용하고 있다.
인터넷은 TCP/IP 기반의 네트워크가 전 세계적으로 확대되어 하나로 연결된 네트워크들의 네트워크, 즉, 수많은 네트워크의 결합체라고 할 수 있다.
웹은 인터넷 기반의 서비스 중 하나인 것이다.
웹에선 서로 통신하기 위해 어떤 규약이 필요한데, 이 규약이 바로 HTTP이다.
1. HTTP (Hypertext Transfer Protocol)란?
- 팀 버너스리(Tim Berners-Lee)와 그 팀은 CERN에서 HTML뿐만 아니라 웹 브라우저 및 웹 브라우저 관련 기술, 그리고 HTTP를 발명했다.
- 문서화된 최초의 HTTP 버전은 HTTP v0.9(1991년)이다.
- HTTP는 서버와 클라이언트가 인터넷 상에서 데이터(동영상, 이미지, 텍스트 등 종류는 상관없다)를 주고받기 위한 프로토콜(protocol)이다.
- HTTP는 계속 발전하여 HTTP/2 버전까지 등장한 상태이다.
아래부터 나올 설명들은 현재 가장 많이 사용되고 있는 HTTP v1.1에 대한 것이다.
2. HTTP 작동 방식
1) HTTP는 서버/클라이언트 모델을 따른다.
클라이언트가 서버에게 요청을 보내면, 서버가 요청을 받아 클라이언트에게 응답을 보낸다.
2) HTTP는 무상태(Stateless) 프로토콜이다.
각 요청을 독립적인 트랜잭션으로 취급한다는 뜻이다. 그래서 클라이언트가 서버에게 요청을 보내기 전에, 클라이언트와 서버를 연결하는 과정이 필요하다. 서버는 응답을 한 후에 클라이언트와의 연결을 끊는다.
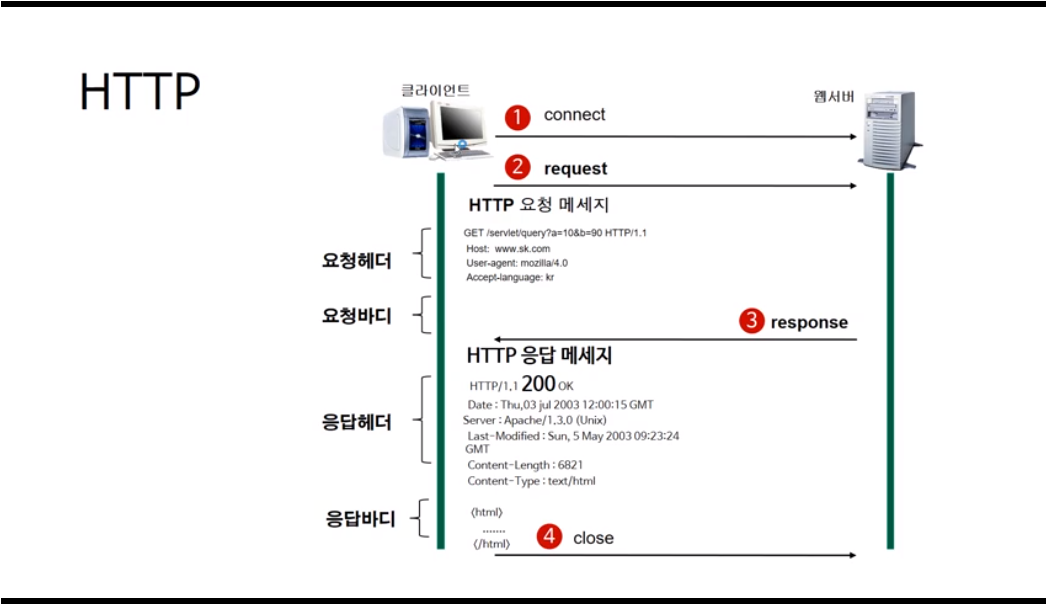
이런 HTTP 작동 방식에 대한 장단점이 있다.
장점)
- 클라이언트와 서버가 계속 연결된 형태가 아니기 때문에, 클라이언트와 서버 간의 최대 연결 수보다 훨씬 더 많은 요청과 응답을 처리할 수 있다.
- 그래서 불특정 다수를 대상으로 하는 서비스에 적합하다고 할 수 있다.
단점)
- 서버가 응답 후 클라이언트와의 연결을 끊어버려, 요청이 들어오는 클라이언트의 이전 상황을 알 수 없다.
(쇼핑몰에서 물건을 고르고 결제를 하려고 할 때, 무슨 물건을 고른지 몰라 결제를 할 수 없을 수 있다.)
- 정보 유지가 필요할 때를 위해 쿠키(Cookie)와 같은 기술이 등장했다.
3. URL (Uniform Resource Locator)
웹상에서 문서, 이미지, 동영상 등 자원의 위치를 나타낸다.
이 위치로 해당 자원에 접근하기 위해 사용된다.
URL은 이렇게 생겼다.
→ http://enai.tistory.com/docs/index.html (가상의 경로)
http는 접근 프로토콜, enai.tistory.com은 도메인 주소, docs는 문서의 경로, index.html은 문서 이름이다.
즉, URL 형태는
접근 프로토콜://IP 주소 or 도메인 주소, 포트 번호/문서의 경로/문서 이름
이렇게 되어있다.
물리적인 서버를 찾기 위해 반드시 필요한 것은 IP 주소나 도메인 주소이다.
이 주소로 물리적인 서버(컴퓨터)를 찾은 후, 해당 컴퓨터 안에서 동작하는 서버를 찾기 위해 포트 값이 필요하다.
(※참고: IP는 집주소, 집 안 각각의 방이 포트, 각 서버는 방(포트)을 하나씩만 차지하고 있다고 생각하면 된다)
하나의 물리적 서버 컴퓨터엔 여러 개의 소프트웨어 서버가 동작할 수 있고, 이 서버는 포트 값이 다 다르게 동작해야 한다. 포트 값은 0보다 큰 숫자 값으로 되어 있고, HTTP의 기본 포트 값은 80이다.
4. HTTP 요청/응답 데이터 포맷
클라이언트가 서버에게 요청 메시지를 보낼 때 정해진 규칙이 있다.
요청 데이터 포맷이라고 한다.
마찬가지로 서버가 클라이언트에게 응답 메시지를 보낼 때도 정해진 규칙이다.
이건 응답 데이터 포맷이라고 한다.
메시지는 헤더, 빈 줄, 바디, 이렇게 세 부분으로 나누어진다.
다시 위의 HTTP 동작 방식에 대한 이미지를 가져오겠다.

화질이 좋지 않아 메시지 내용이 흐릿하게 보이지만,
요청 메시지에서 헤더 부분의 내용부터 보겠다. (헤더는 필수 요소이다)
1) 요청 데이터 포맷
첫번째 줄부터 보겠다.
제일 처음에 GET이라고 적힌 것을 볼 수 있다. 이 부분이 요청 메서드이다. 서버에게 요청의 종류를 알려주기 위한 용도이다.
다음에 적힌 servlet/query?a=10&b=90은 요청 URI라고 하며, 요청하는 자원의 위치를 명시해주는 부분이다.
마지막에 HTTP/1.1은 HTTP 프로토콜의 버전이다. 웹 브라우저가 사용하는 프로토콜의 버전을 명시해주는 부분이다.
요청 메서드의 종류는 다음과 같다. (참고로 초기 웹 서버는 GET 방식만 지원해주었다고 한다)
- GET: 정보 요청 (SELECT)
- POST: 정보 넣기 (INSERT)
- PUT: 정보 업데이터 (UPDATE)
- DELETE: 정보 삭제 (DELETE)
- HEAD: HTTP 헤더 정보 요청 (해당 자원이 존재하는지 혹은 서버에 문제가 없는지 확인하기 위해 사용)
- OPTIONS: 웹 서버가 지원하는 메서드 종류 요청
- TRACE: 클라이언트의 요청 그대로 반환 (주로 echo 서비스로 서버 상태를 확인하기 위한 목적으로 사용)
두 번째 줄부터는 여러 줄의 헤더의 정보가 나온다.
각각의 줄은 헤더 명과 헤더 값이 콜론(:)으로 구분되어 있고,
각 줄은 라인피드와 캐리지 리턴으로 구분된다.
그 다음 빈 줄이 나온다.
다음은 요청 바디 부분인데, 보면 아무것도 없다.
여긴 요청할 때 가지고 가야 되는 자원들이 명시되는 부분이다.
요청 메서드가 GET이었는데, GET은 요청할 때 가지고 갈 자원이 없는 메서드이기 때문에 요청 바디가 비어있다.
요청 메서드가 POST이거나 PUT일 때 요청 바디에 값이 들어온다.
2) 응답 데이터 포맷
첫 줄에는 반드시 응답 HTTP 프로토콜 버전이 나와야 한다. 그 옆에 응답 코드, 응답 메시지 등이 나올 수 있다.
나머지 헤더 부분은 날짜, 웹 서버의 이름과 버전, 콘텐츠 타입, 캐시 제어 방식, 콘텐츠 길이 등의 값이 나온다.
헤더 부분이 끝나면 빈줄이 나오고,
응답 바디 부분이 나온다.
여긴 실제 응답 리소스 데이터가 나오는 부분이다.
5. HTTPS (Hyper Text Transfer Protocol over Secure Socket Layer)
많이들 아는 유명한 사이트의 URL을 보면 http가 아닌 https가 붙여져 있는 것을 볼 수 있다.
해당 문서는 HTTPS로 접근해야하기 때문이다.
HTTPS는 HTTP의 보안이 강화된 버전이다.
HTTPS는 SSL(Secure Socket Layer)로 세션 데이터를 암호화하여 데이터를 보호한다.
좀 더 자세한 설명이 되어 있는 사이트 참고: Http와 Https 이해와 차이점 그리고 오해(?)
Http와 Https 이해와 차이점 그리고 오해(?)
HTTPS (feat. http) HTTPS에 대해 알아보기 전에 HTTP를 간단하게 설명할 수 있으면 좋다. HTTP는 HyperText Tranfer Protocol로 WWW상에서 정보를 주고 받는 프로토콜이다. 클라이언트인 웹브라우저가 서버에 HTT..
jeong-pro.tistory.com
출처)
edwith 부스트코스 웹 프로그래밍
위키백과
- HTTPS
'etc > Web' 카테고리의 다른 글
| 로컬 테스트 서버 Python의 SimpleHTTPServer (0) | 2019.10.07 |
|---|---|
| 파일 업로드 & 다운로드 (1) | 2019.09.13 |
| 웹 프론트엔드 개발자가 공부할 것들 (0) | 2019.09.10 |
| 웹 프로그래밍을 위한 프로그래밍 언어 (0) | 2019.08.20 |
댓글